Материал из MachineLearning.
Similarity Miner — учебный студенческий проект,
программа для решения задач классификации на основе обучаемых функций сходства.
Базовые требования
- Исходными данными является матрица объекты–признаки. Решается задача классификации на два класса.
- Для классификации используется метод ближайших соседей. Число соседей и вид ядра должны подбираться автоматически.
- Основная задача — найти метрики (функции сходства объектов, similarity functions), во-первых, обладающие хорошим качеством классификации; во-вторых, хорошо интерпретируемые, то есть зависящие от небольшого числа признаков.
- Метрика — взвешенная евклидова. Веса признаков в метрике должны настраиваться автоматически.
- Процесс подбора метрики может происходить как полностью автоматически, так и под контролем пользователя.
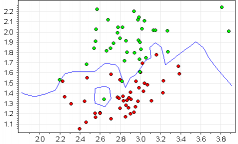
Пример. Выборка и разделяющая кривая.
- С точки зрения пользователя процесс подбора метрики заключается в разглядывании серии графиков. Каждый график отображает выборку и разделяющую кривую; по осям могут откладываться как исходные признаки, так и новые, синтезированные программой. Графики позволяют увидеть задачу в различных разрезах и оценить, насколько улучшается качество классификации по мере добавления признаков в метрику. Ничего более сложного пользователю предлагать нельзя.
- Программа сама должна отбирать и показывать пользователю только наиболее интересные графики. Пользователь должен иметь возможность «забраковать» метрику, если график ему «не нравится» или если он считает сочетание признаков в данной метрике неинтерпретируемым.
Идеи синтеза признаков
- Если уже есть kNN классификатор, то расстояние до разделяющей поверхности можно рассматривать как новый признак.
Дополнительные требования
- Число классов может быть произвольно. Реализовать стратегию «каждый против всех».
- Число объектов может быть как маленьким (десятки), так и большим (миллионы). Реализовать отбор эталонных объектов.
- Число признаков может быть как маленьким (единицы), так и большим (тысячи). Применить эвристики сокращения перебора.
- Должна автоматически строиться композиция из нескольких лучших kNN-классификаторов.
- Программа должна быть доступна в Интернет через веб-интерфейс.
Ссылки

